Demo Vids: https://youtu.be/EAv7olLFaek, https://youtu.be/oWKc6HfKZ_M
Github Repository: https://github.com/mbird1258/Body-Matching, https://github.com/mbird1258/Volleyball-Tracking
Premise
My plan for this project was to make use of 2 cameras and a variety of methods to detect/track objects in videos in order to map them in 3D. This way, it would be possible to make a 3D video that could be viewed frame by frame or as in the form of a continuous video in order to analyse volleyball games. This was largely motivated by my interest in and good body type for volleyball but terrible skills to accompany.
Recording the Video
The stand used was pretty flimsy and cracked in a few areas, which ended up causing me quite a bit of trouble. For aligning the frames of the video, I suggest taking a fast movement such as an eye blinking to align the two videos. In addition to this, it can be useful to run the following command to show the exact time and frame of a video (at least for quicktime player on mac):
ffmpeg -i input.mp4 -c copy -timecode 00:00:00:00 output.mp4
It’s important to make sure that both videos have the same framerate as well. The frame rate can be changed with the following command:
ffmpeg -i input.mp4 -c copy -r [fps] output.mp4
Body
The body detection was done through the use of RTMO, which I found to be much more robust than other libraries like mediapipe. It was a bit of a pain to set up until I found RTMLib(linked on the RTMO github which I annoyingly missed), but using RTMLib was simple enough.
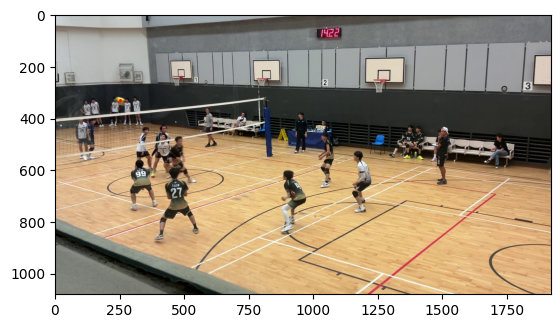
Image of RTMO applied to image of game

To accomplish body matching, I took each body and normalized the average of the positions of each joint to 0. Then, I calculated the smallest distance between corresponding joints between each body in the first image and each body in the second image and took the match with the lowest error. This works largely because the distance between the two cameras was largely insubstantial compared to the distance the bodies were from the cameras, meaning that the rotational and scaling effect of a different camera position was largely minimized.
Matched bodies
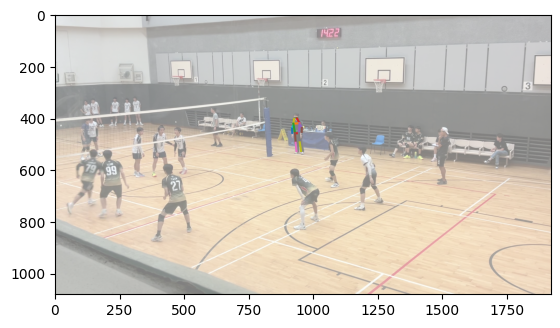
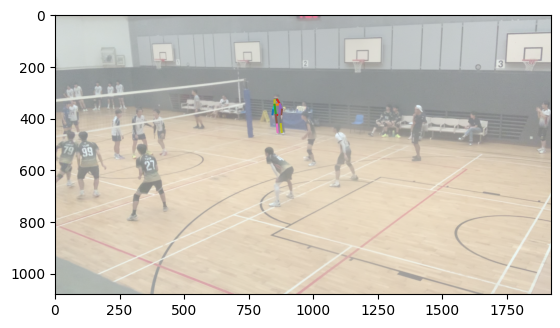
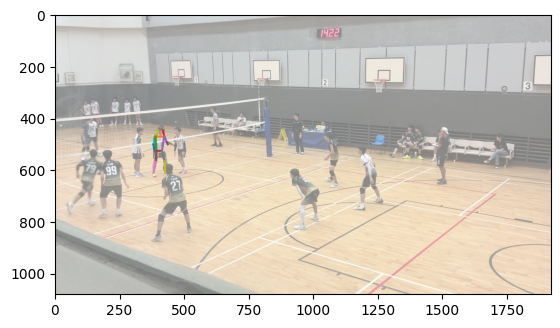
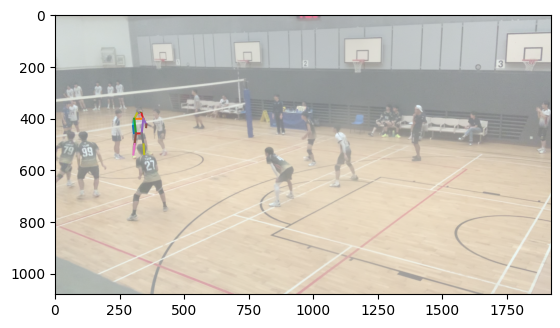
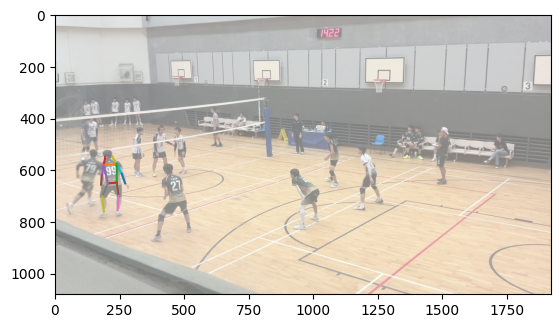
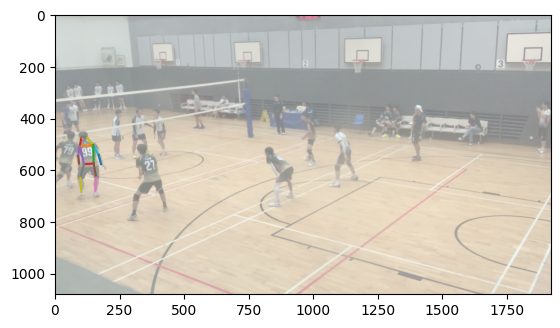

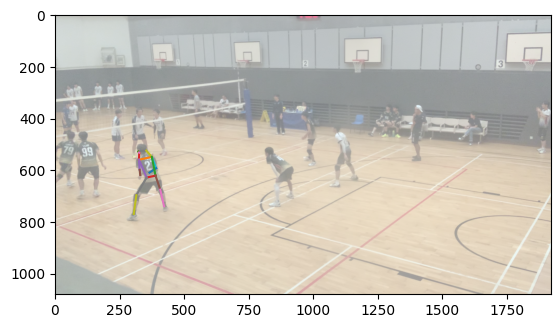
Volleyball
In order to track the volleyball, I went through a lot of solutions online, including a large amount of machine learning models on roboflow and some algorithms online on GitHub, but they were all either not robust enough or I encountered a lot of issues implementing them.
In the end, I decided to come up with my own solution, which involved creating a mask of all moving objects in the frame, creating a mask of all objects fitting within the correct color range, and taking the largest contour/blob of pixels that satisfy both conditions. More specifically, to detect motion within the image, I took the median of the last 60 or so frames, giving us an image of the court without any people or balls, and took the difference in colour between this median and the current frame.
Input
Median
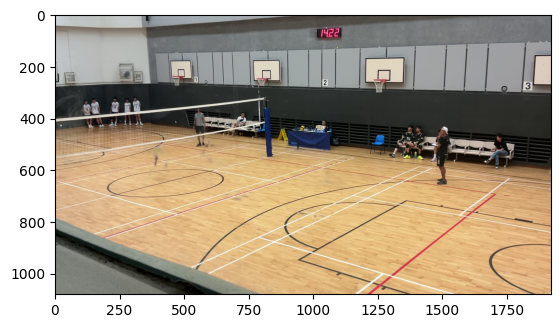
Movement mask
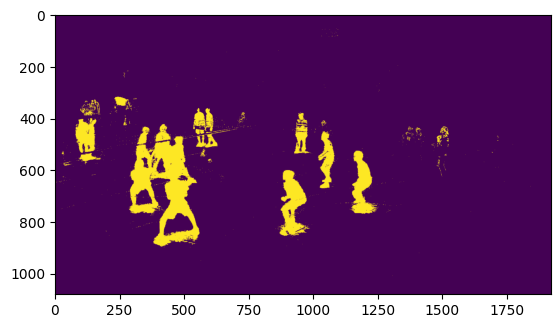
Colour Mask
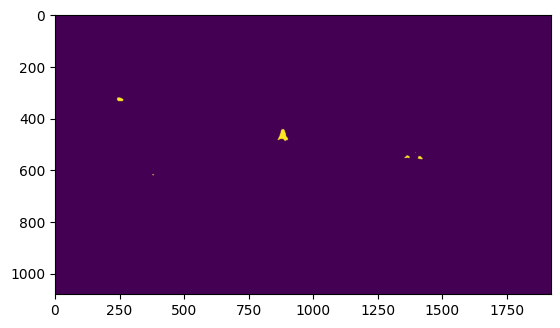
Combined Mask
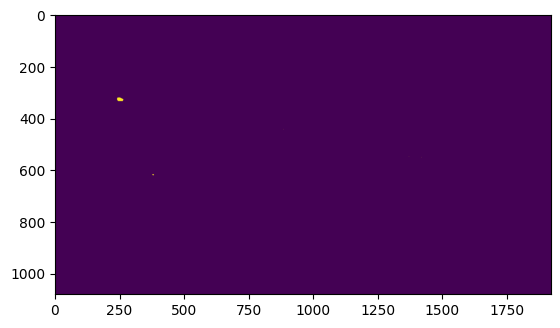
Ball Detection
Eyes
Finding the center of the eye
I had originally intended to use the eye matching for each of the individual players on the court, but considering that almost all the players’ eyes are hidden by their heads and the resolution and robustness of the ML algorithms I used would lead to results that are too inconsistent to rely upon. However, I still tried to implement it as a sort of separate mini-project to track the position of the eye’s focus in short range.
The math behind finding the centers of the spheres isn’t too difficult. The formula for a sphere, given that the center of the sphere is (x,y,z), is:
By expanding, we get the following equation:
Since we are solving for x, y, and z, we can plug in values from a point we know lies on the surface of the sphere (thus satisfying the equation) in for x1, y1, and z1, thus allowing us to treat x1, y1, and z1 as constants. Solving for x, y, and z on the left, we get:
Crucially, since we want to remove the x2, y2, z2, and r2 from the equation, if we now consider the 2 equations defining 2 points and subtract them from each other, we get:
Since we have 3 unknowns, we need 3 equations, thus requiring 4 points.
Writing this in matrix form such that we can solve it, we get the following:
Solving this matrix then returns the coordinates of the center of the sphere. Doing this for every combination of 4 points out of the points we have on the surface of the eye and applying RANSAC with the radius being constrained to around 1.15 cm gives us a pretty good approximation of the center of the eye.
The points of the surface of the eye can be determined with two cameras, by first using machine learning to find corresponding points on the eye on each image, then finding the intersection of the corresponding two lines drawn in 3D space.
Iris triangulation
In order to find the center of the iris, we once again employ machine learning to detect the position of the iris on screen in images from two cameras and follow the same procedure in the above paragraph to triangulate the position of the iris.
Focus triangulation
In order to find the point in 3D space that the person is focusing on, we can draw a line from the center of each eye to the corresponding iris position in 3D space, then find the intersection between these two lines.
Results
It ended up not working :( . None of the off the shelf face landmarking machine learning models were capable of finding points on my eyes that were accurate enough across both images to triangulate in 3d and use to get a clean sphere. Every time, I would end up with a sphere roughly two times too big for a human eye, and oftentimes the eye landmarks wouldn’t even be on my eye in the 2d images. Overall, I tried multiple models including mediapipe, dlib, openface, retinaface, MTCNN, SPIGA, yolov8-face, RTMPose wholebody, and more, and none seemed to work well enough. The fact that these models aren’t perfectly accurate and my method to triangulate focus from images has a very low tolerance for inaccuracy led to results that were unfortunately completely unusable. I also tried to use a different sphere finding algorithm, and it worked quite well but still couldn’t overcome the inaccurate eye landmarks and couldn’t constrain the eye radius like RANSAC could.
Mapping Court Points
The court points’ position on each image was determined through manual input, which I decided would be best given that it only needs to be done once for a long video. In order to get the full court when most of the court was cropped out by the restricted cameras’ field of views, I estimated each point defining the court from just 3. This is done by manually inputting 3 of the court points and finding their position in 3D, rotating the 3 points to have the same z value in space, rotating and translating hard coded 3d points that define the entire volleyball court such that the 3 inputted points and the corresponding hard coded points align, and then reversing the rotation we performed to make the 3 points have the same z value in space.
Floundering Around With Mapping
Originally, mapping shouldn’t have been much of an issue. Given two images with a field of views of both and the offset in position between the two, using the formula found here(shortest line between two lines in 3D). Thus, since we have the matched points of each body’s joints and the volleyball, we could just find their most likely position in 3D space. However, this didn’t really go as planned.
The first hurdle was finding the field of view of the ipad and iphone that I used. I ended up sinking hours into different methods before finding this, which I think gave the best results. I also spent an hour or two checking the camera offset of the cameras in my camera setup over and over again, changing absolutely nothing.
The next hurdle was the shoddy 3D printed setup I used for positioning the cameras stationary relative to each other, which ended up leaving one camera’s orientation different from the other when the code assumed they were identical. This tiny offset in rotation led to a large offset in position of pixels in the image, which was further exacerbated by the large distance between the camera and the bodies and the low distance between cameras.
In order to solve this, I used something called a homography matrix. The homography matrix effectively transforms, rotates, shears, and warps the image such that given a rectangle can be remapped to any quadrilateral. This allows the changing of the perspective of an image, thus why it is sometimes called the perspective projection matrix, which if calibrated correctly could solve any problems to do with rotation or incorrect positioning of the second camera. To solve for the homography matrix which has 8 degrees of freedom, we need 4 points on the image and the 4 new points we want to obtain. This is obtained by finding the position of court points in 3D and projecting those onto the image plane of the second camera as the target points. Then, using those target points and the originally found points of the court on the image, we can calculate a homography matrix. Unfortunately, this only improved the results and failed to magically solve all my problems.
My only possible explanation remaining for the triangulation still not working is that the terrible recording setup, far distance of the court from the camera, relatively small distance between the two cameras, and natural inaccuracy all work in conjunction to make the project fail.
Conclusion
The original intent of the project - mapping an entire volleyball game in 3D - failed. Regardless, the project is up on GitHub, as others can use it as a reference, and if hardware was really the issue, the software is probably somewhat correct. In addition to this, the project successfully accomplished tracking of volleyballs and matching bodies between two images, which each have been posted as individual GitHub projects too. Volleyball Body matching Eye focus mapping
In the future I might come back to this project with a proper recording setup since it has quite a bit of potential in volleyball analytics, as I had originally planned to make a nice frontend for it and have it calculate the ball velocity and acceleration, body joint velocity and acceleration, jump height, spike speed, compare bumping/setting/spiking form etc.